안녕하세요. 씨앤텍 시스템즈 입니다.
이번 글은 R을 활용하여 빅데이터 처리해보는 과정을 정리해보도록 하겠습니다.
먼저 사용환경부터 세팅해보도록 하겠습니다.
운영체제는 윈도우 입니다.
https://cran.r-project.org/bin/windows/base/
Download R-3.6.2 for Windows. The R-project for statistical computing.
If you want to double-check that the package you have downloaded matches the package distributed by CRAN, you can compare the md5sum of the .exe to the fingerprint on the master server. You will need a version of md5sum for windows: both graphical and comm
cran.r-project.org
먼저 위 사이트로 가셔서 윈도우용 R을 다운로드 받습니다.
https://rstudio.com/products/rstudio/
RStudio
Take control of your R code
rstudio.com
그리고 R스튜디오도 다운받아 줍니다.
R을 사용할 수 있는 툴로 R스튜디오와 주피터 노트북이 있는데, 저는 이번에 주피터 노트북을 사용해보았습니다.
주피터 노트북을 사용하고 싶으시다면 아나콘다를 다운 받으셔야 합니다.
https://www.anaconda.com/distribution/
Anaconda Python/R Distribution - Free Download
Anaconda Distribution is the world's most popular Python data science platform. Download the free version to access over 1500 data science packages and manage libraries and dependencies with Conda.
www.anaconda.com
python3.7버전을 다운받아주세요~!!
그리고 R Kernel를 설치하기 위해서 시작버튼을 누르고 Anaconda prompt로 들어가 아래와 같이 입력해 줍니다.
| conda install -c r r-essentials |

그리고 위와 같이 jupyter notebook을 넣고 엔터를 치면 아래와 같이 localhost로 하여 주피터 노트북이 생성됩니다.

오른쪽 위에 New 탭을 누르시고 R 버튼을 누르시면 아래와 같이 컬럼이 생깁니다.

이제 모든 준비가 완료되었습니다!
사실 주피터 노트북, 파이썬, R 등을 통해서 데이터를 그래프화 시키기 위해서는 정제화된 데이터 파일이 필수적이고
데이터 정리 작업에서 정제화 시키는 것이 거의 70~80%를 차지하고
나머지는 각 언어 문법에 맞추어 그래프 그리는 것이라고 보시면 될 것 같습니다.
여기서는 이미 정제화된 데이터를 가지고 막대그래프를 그려보도록 하겠습니다.
먼저 주피터 노트북에서 파일을 저장하는 현재 위치를 알아보도록 하겠습니다.

위와 같이 getwd()를 넣고 Shift+Enter를 누르면 어디에 있는지 알려줍니다.
그럼 그 위치에 정제된 csv 파일을 복사하여 붙여넣어줍니다.
해당 파일은 아래 다운받으시기 바랍니다.
직위에 따른 연봉 데이터 입니다.
참고로 그냥 엔터를 누르면 컬럼이 하나 추가되고,
실행되기 위해서는 shift+ enter를 누르셔야 합니다. (엑셀과 비슷?한듯 합니다)
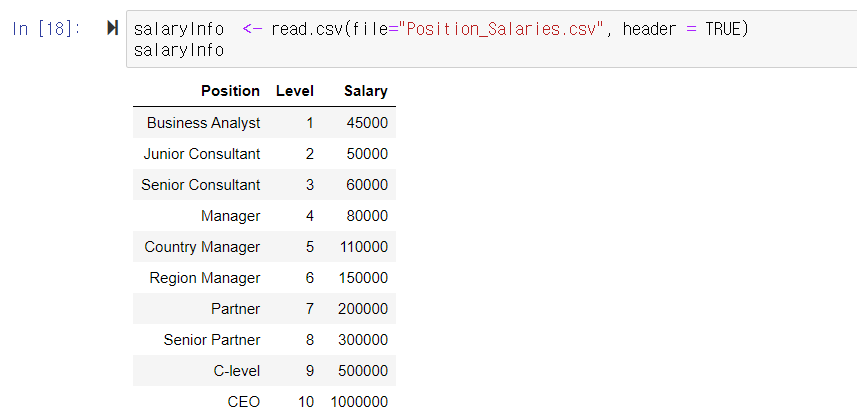
위와 같이 salaryInfo 테이블에 csv 파일을 넣어보도록 하겠습니다.
<- 는 Alt + - (알트 + 마이너스 키) 누르시면 됩니다.
| salaryInfo <- read.csv(file="Position_Salaries.csv", header = TRUE) salaryInfo |
그리고 그래프를 그리기 앞서 패키지를 설치해야 합니다.
install.packages("tidyverse")
install.packages("plotly")
위와 같이 입력한 뒤 패키지가 성공적으로 설치되고 나면
library(tidyverse)
library(ggplot2)
도 입력해줍니다.
ggplot2는 그래프를 그릴 수 있는 라이브러리라고 보시면 되겠습니다.
ggplot을 이용하여 포인트를 찍는 그래프를 그려보겠습니다.
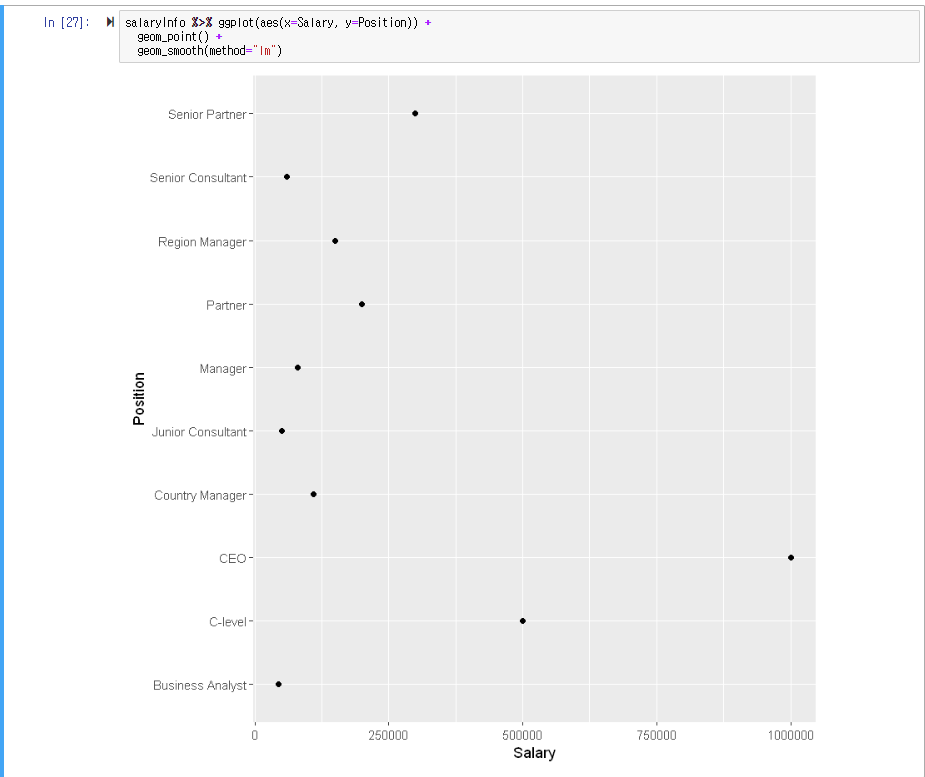
위와 같이 27번 컬럼의 내용을 적어주면 그래프가 나오게 됩니다.
| salaryInfo %>% ggplot(aes(x=Salary, y=Position)) + geom_point() + geom_smooth(method="lm") |
%>%의 단축키는 ctrl+shift+m 입니다.
하지만 뭔가... 눈에 확 들어오지는 않지요?
데이터에 따라서 어떤 그래프를 그려야 사용자가 직관적으로 알 수 있을지도 고민하여
그래프를 선택하여 그리는 것도 매우 중요합니다.!
그러면 이번엔 막대그래프(히스토그램)을 통해 그려보도록 하겠습니다.
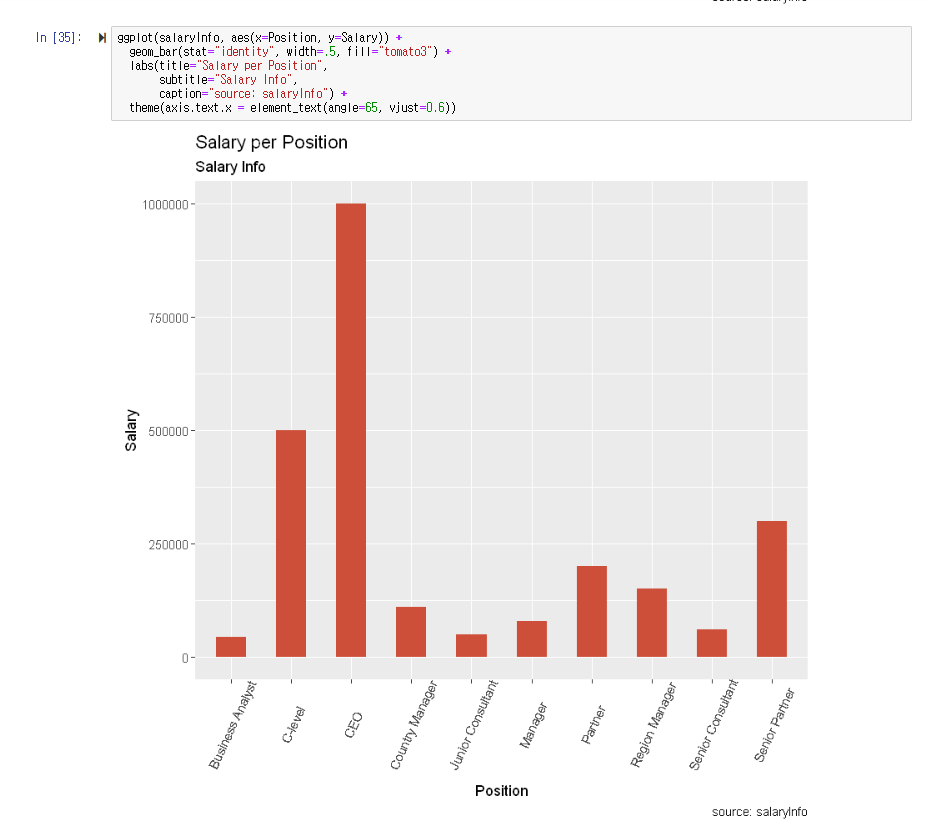
컬럼 35의 내용을 적어주시면 됩니다.
| ggplot(salaryInfo, aes(x=reorder(Position,Level), y=Salary)) + geom_bar(stat="identity", width=.5, fill="tomato3") + labs(title="Salary per Position", subtitle="Salary Info", caption="source: salaryInfo") + theme(axis.text.x = element_text(angle=65, vjust=0.6)) |
쉽지요?
그런데 저는 여기서 직위 (ABC순)가 아닌, 연봉에 따라서 정리하고 싶습니다.
어떻게 해야할까요?

위와 같이 reorder를 써주면 됩니다.
reorder 함수를 사용해서 ggplot 함수내에서 정렬도 가능 합니다.
position을 level 즉 연봉에 따라서 정렬한다는 의미입니다.
| ggplot(salaryInfo, aes(x=reorder(Position,Level), y=Salary)) + geom_bar(stat="identity", width=.5, fill="tomato3") + labs(title="Salary per Position", subtitle="Salary Info", caption="source: salaryInfo") + theme(axis.text.x = element_text(angle=65, vjust=0.6)) |
위와 같이 R을 활용한 데이터 처리 활용 방법에 대해서 알아보았습니다.
라이브러리 ggplot을 활용하면 그래프를 그릴 수 있어 R 문법을 잘 알아두면 유용할 것 같다는 생각이 듭니다.
하지만 이런 처리를 위해서는 데이터 정제화 작업이 필수이고 매우 중요하다는 점도 염두에 두시기 바랍니다.
감사합니다.
'Data > Bigdata' 카테고리의 다른 글
| Spark DataFrame (PySpark) (0) | 2020.04.20 |
|---|---|
| R을 이용한 Bioinformatics (Bioconductor) (1) | 2020.04.20 |
| Apache Spark 기능 (0) | 2020.02.13 |
| Elastic Search란? (0) | 2020.01.20 |
| Apache Spark란? (0) | 2020.01.09 |