
안녕하세요.
CKAN의 중요 한 축을 담당하고 있는 검색엔진 Solr에 대해 알아보겠습니다.
Apache Lucene(루씬)은 자바 언어로 이루어진 정보 검색 라이브러리입니다. Solr와 Elasticsearch 검색엔진은 루씬을 기반의 API입니다.
실제로 CKAN 내부에서 Solr 라이브러리를 보면 루씬 라이브러리가 포함되어있는 것을 볼 수 있습니다.

Solr나 Lucene은 페이스북이나 트위터 등 다들 알고 있는 기업의 제품에 인베디드돼 이용되고 있습니다.
CKAN에서는 이러한 Solr를 어떻게 적용했고 어떤 구조로 되어있는지 정리했습니다.
우선 Solr 디렉토리먼저 살펴보겠습니다.
'/etc/solr' : solr 설정 파일이 들어있는 디렉토리입니다.
'/usr/share/solr' : solr 소스 파일이 들어있는 디렉토리입니다.
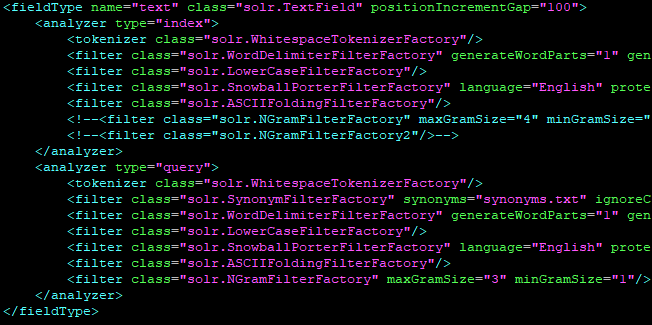
schema.xml에서 '<그림 1-1>'에 있던 라이브러리를 사용하여 인덱싱 및 쿼리의 기능을 추가할 수 있습니다.
문장을 토큰으로 비유하고 문장을 'tokenizer'를 통해 서브토큰으로 나눕니다. 서브토큰을 이용해서 filter 기능을 수행합니다.
Solr에서 제공해주는 기능은 Solr Ref Guide 6.6를 통해서 확인하실 수 있습니다.
Solr에서 제공해주는 기능 외에 사용자가 원하는 방식으로 수정하고 싶어서 '<그림 1-1>'에 있는 라이브러리를 수정하여 기능을 추가할 수 있습니다.
Ubuntu OS에서 분석 및 소스 추가에 어려움이 있어 윈도우에서 진행하였습니다.
jar파일의 압축을 해제하고 내용을 확인해본 결과 class파일로 묶여있는 것을 확인할 수 있습니다.

'<그림 2-2>'에서는 클래스파일을 jad라는 디컴파일툴을 이용하여 디컴파일을 진행하였습니다.

IDE는 원하시는 걸로 사용하시면 됩니다. 저는 이클립스를 사용하여 디컴파일한 소스파일을 수정해서 컴파일하는 방식으로 진행하였습니다.
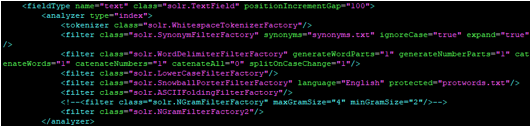
'<그림 1-1>'에 추가 또는 수정된 라이브러리 파일을 서버에 올리고 schema.xml에 해당 부분을 작성해주시면 됩니다.
이상으로 CKAN에서 검색엔진 Solr에 대해 정리해보았습니다.
감사합니다.
'OpenDataPlatform > CKAN 분석' 카테고리의 다른 글
| ckanext-Harvest 설치 및 데이터 불러오기 (0) | 2020.04.21 |
|---|---|
| 03. CKAN 프레임워크 - Pandas (1) | 2019.07.01 |
| 01. CKAN 프레임워크 - 준비 (0) | 2019.05.09 |
| CKAN DataSet 등록 시 사용된 테이블 분석 (1) | 2019.05.09 |
| Postgresql Query Log 분석 (0) | 2019.05.09 |