안녕하세요, 씨앤텍시스템즈입니다.
본 포스팅에서는 최근 개인정보보호 이슈와 함께 부상하고 있는 연합학습에 대해서 알아보겠습니다.
연합학습은 구글에서 제안된 기법으로 개인 모바일 기기에 저장된 데이터를 이용하여 인공지능 모델을 학습하고 이를 취합하여 범용적인 인공지능 모델을 만드는 기법입니다. 현재 대부분의 인공지능 모델 학습 방법은 모든 학습데이터를 한곳에 통합하고 이를 이용하는 방법으로 개인정보보호 및 보안상의 이유로 중앙 데이터 저장소로 이동하기 어려운 데이터에 대해서는 적용하기 어려운게 사실입니다.

최근 특히 개인정보에 민감한 의료 분야에서 연합학습을 적용하고자 많은 연구개발이 이루어지고 있습니다. 의료정보를 통합하거나 공유하지 않고 의료기관 내부에서 인공지능 모델을 학습하고 학습된 정보만을 이용하여 다기관에 적용할 수 있는 인공지능 모델을 개발할 수 있기 때문입니다. 해외에서도 엔비디아 자사 서비스인 클라라 연합학습을 이용하여 매사추세츠 제너럴 브리검 병원과 함께 코로나19 환자의 산소요구량 예측하는 인공지능 모델을 개발하였고, 이 모델을 개발하게 위해 전 세계 20개 병원이 참여하여 연합학습 이니셔티브인 EXAM(EMR CXR AI Model)을 시작하였습니다.
인텔은 펜실베이나 대학교 페럴만 의과대학과 협력하여 뇌종양 식별 인공지능 모델을 개발하고 있습니다. 의료영상 영역에서 연합학습을 이용한 논문을 최초로 발표했으며, 기존 프라이버시가 보존되지 않는 모델 정확도의 99%이상으로 연합학습을 이용하여 모델을 훈련시킬 수 있다는것을 입증하기도 하였다.

연합학습이 학습되는 과정을 좀 더 살펴보면, 개인 모바일 기기에 저장된 데이터를 이용하여 인공지능 모델이 학습되고(A), 다양한 사용자의 개인 모바일 기기에서 학습된 파라미터 정보가 글로범 모델의 정보가 있는 중앙서버로 전송됩니다.(B) 전송된 파라미터를 이용하여 중앙 서버에서는 글로벌 모델을 학습하고 이를 다시 개인 모바일 기기로 전송하는데 이 과정을 반복하게 됩니다.(C)
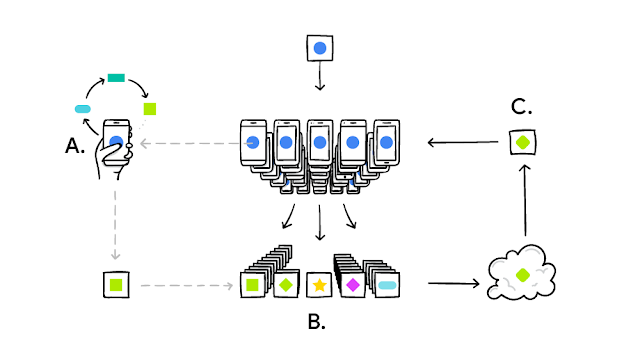
연합학습은 개인 모바일 기기에서 자원이 많이 필요한 인공지능 모델이 학습되기 때문에 성능에 영향을 줄 수 있습니다. 그래서 연합학습은 사용자가 모바일 기기를 사용하지 않는 시간을 활용하고 모델 파라미터 정보 전송에 네트워크 비용이 발생 할 수 있어 무료 와이아피에 접속되어 있을 경우에 전송하게 됩니다.

현재 연합학습은 구글의 자사 키보드인 GBoard에 적용되어 있으며, 사용자가 키보드에 단어를 입력할 때 이에 알맞는 단어를 추천하는 기능으로 서비스 되고 있습니다.

연합학습을 구현하기 위해서는 직접 구현할 수도 있지만, 이미 Tensorflow에 반영되어 있어 이를 이용하여 쉽게 연합학습을 구현할 수 있습니다.
https://www.tensorflow.org/federated?hl=ko
TensorFlow Federated
분산 데이터에 대한 머신 러닝 및 기타 계산을 위한 오픈 소스 프레임워크입니다.
www.tensorflow.org
<연합학습 예시 코드>
import tensorflow as tf
import tensorflow_federated as tff
# Load simulation data.
source, _ = tff.simulation.datasets.emnist.load_data()
def client_data(n):
return source.create_tf_dataset_for_client(source.client_ids[n]).map(
lambda e: (tf.reshape(e['pixels'], [-1]), e['label'])
).repeat(10).batch(20)
# Pick a subset of client devices to participate in training.
train_data = [client_data(n) for n in range(3)]
# Grab a single batch of data so that TFF knows what data looks like.
sample_batch = tf.nest.map_structure(
lambda x: x.numpy(), iter(train_data[0]).next())
# Wrap a Keras model for use with TFF.
def model_fn():
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(10, tf.nn.softmax, input_shape=(784,),
kernel_initializer='zeros')
])
return tff.learning.from_keras_model(
model,
dummy_batch=sample_batch,
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()])
# Simulate a few rounds of training with the selected client devices.
trainer = tff.learning.build_federated_averaging_process(
model_fn,
client_optimizer_fn=lambda: tf.keras.optimizers.SGD(0.1))
state = trainer.initialize()
for _ in range(5):
state, metrics = trainer.next(state, train_data)
print (metrics.loss)